今回で最後のメモとなる。前回までで、管理コンソールにブラウザで接続できたため、残りのクラスタ作成、共有ディスクの接続、仮想マシンのプロビジョニングのメモを残す。
※現在は、HPE VM Essentialsではなく、HPE Morpheus VM Essentials Software (HVM)
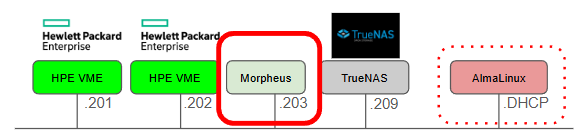
環境の構成
今回の作業内容は、構成図に示す赤枠のMorpheusにブラウザでアクセスし、作業をする。
クラスタの作成
前回は、ブラウザでアクセスし、下図の状態までメモを残した。今回はこの後からのメモを残す。
テナント名を入力し、「次へ」を選択。
マスターユーザ作成の画面で必要な情報を入力する。メールアドレスも記入が必須となる。
初期セットアップ画面で、必要な情報を入力する。
評価版のため、ライセンスキーの入力画面は空欄のままで、「セットアップ完了」を選択する。
上記作業が完了すると、TOP画面が表示される。
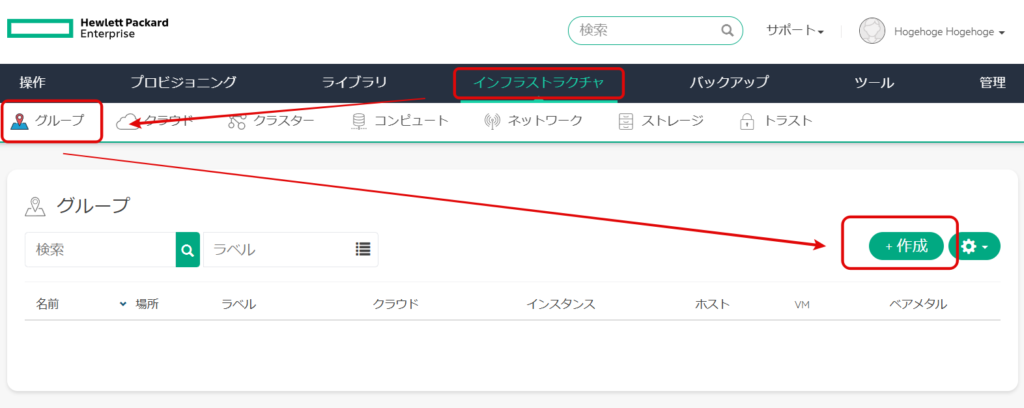
マニュアルに沿って、「グループ」、「クラウド」、「クラスター」、「コンピュート」を順次設定する。
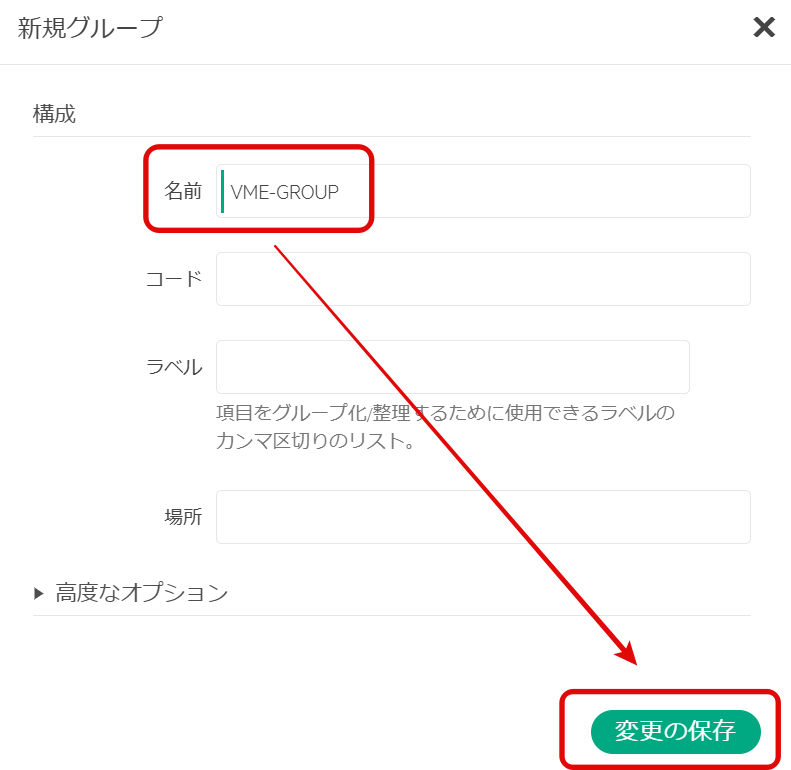
グループ名を入力し、「変更の保存」を選択する。
「クラウド」 → 「追加」を選択する。
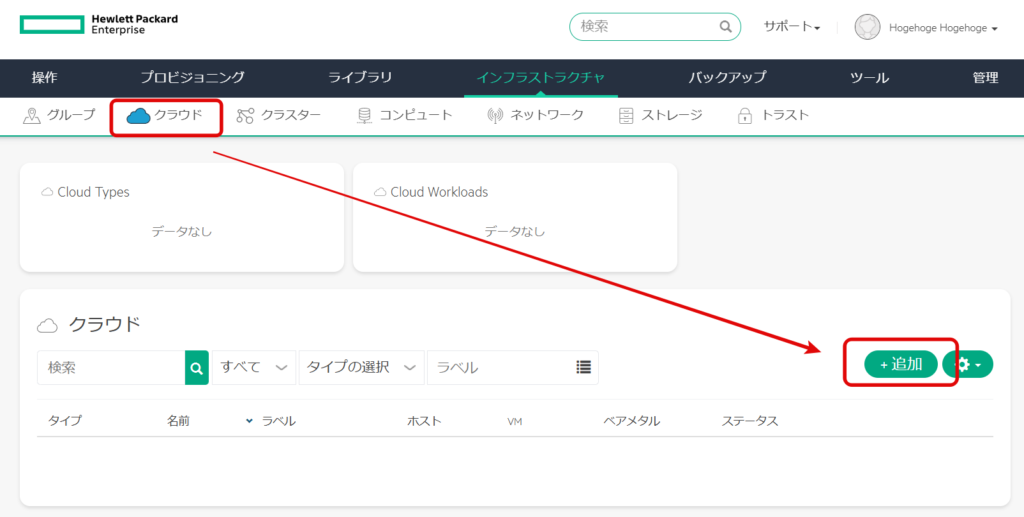
VMEはvCenterも管理できるが、本検証環境には存在しないため、「MORPHEUS」を選択し「次へ」を選択。
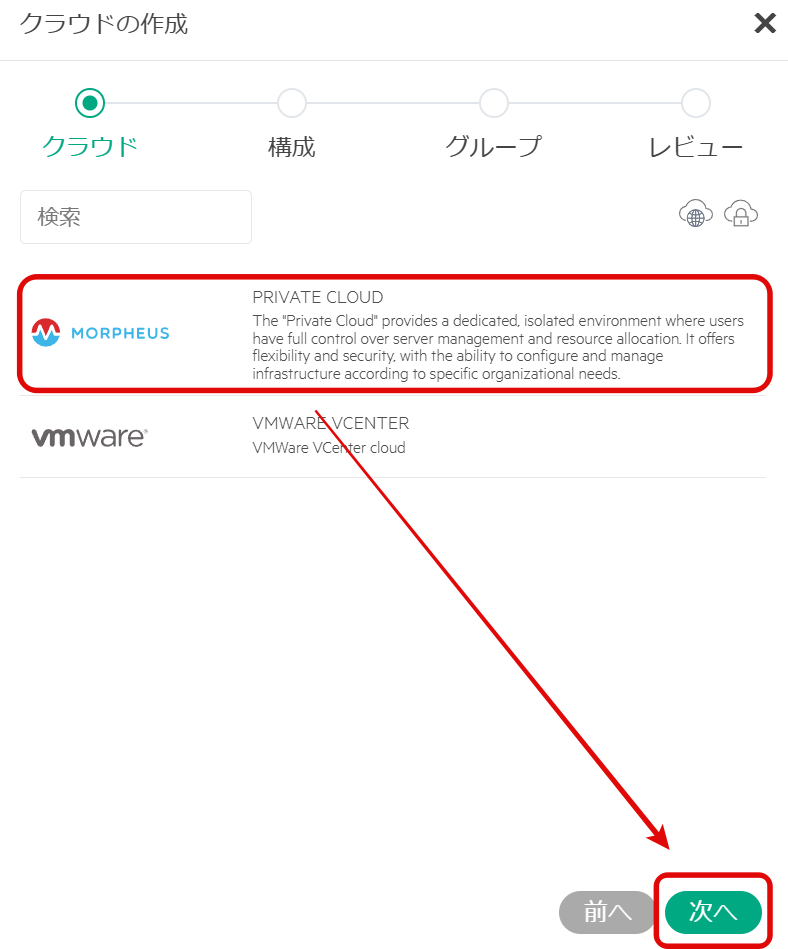
クラウド名を入力し、「次へ」を選択する。
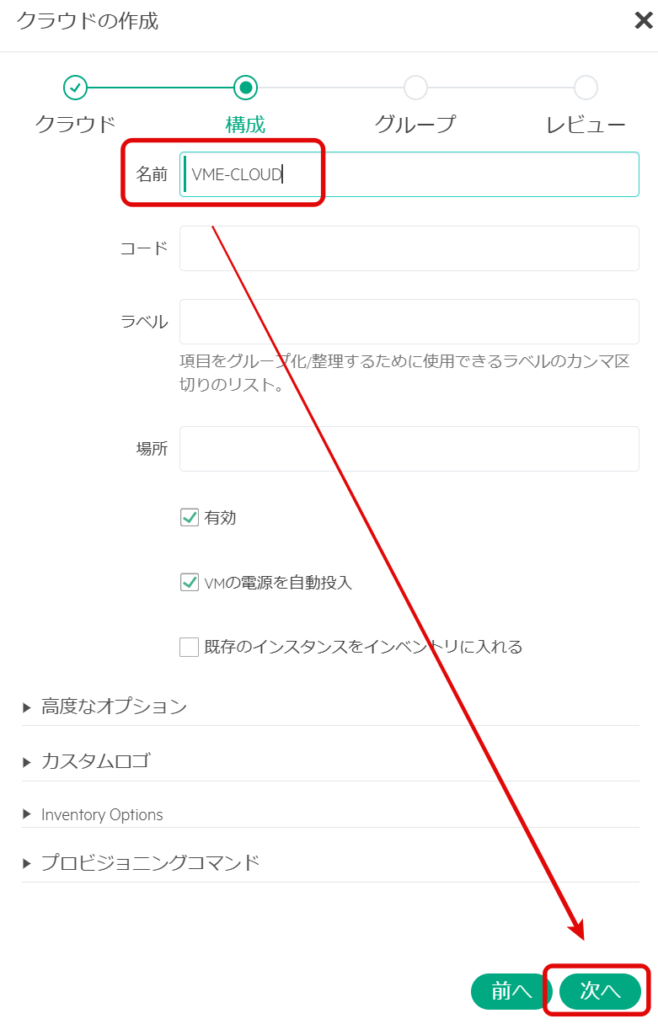
先ほど作成したグループを選択し、「次へ」を選択する。

内容を確認し、問題がなければ「完了」を選択する。

ステータスが、「INITIALIZING」となっている。
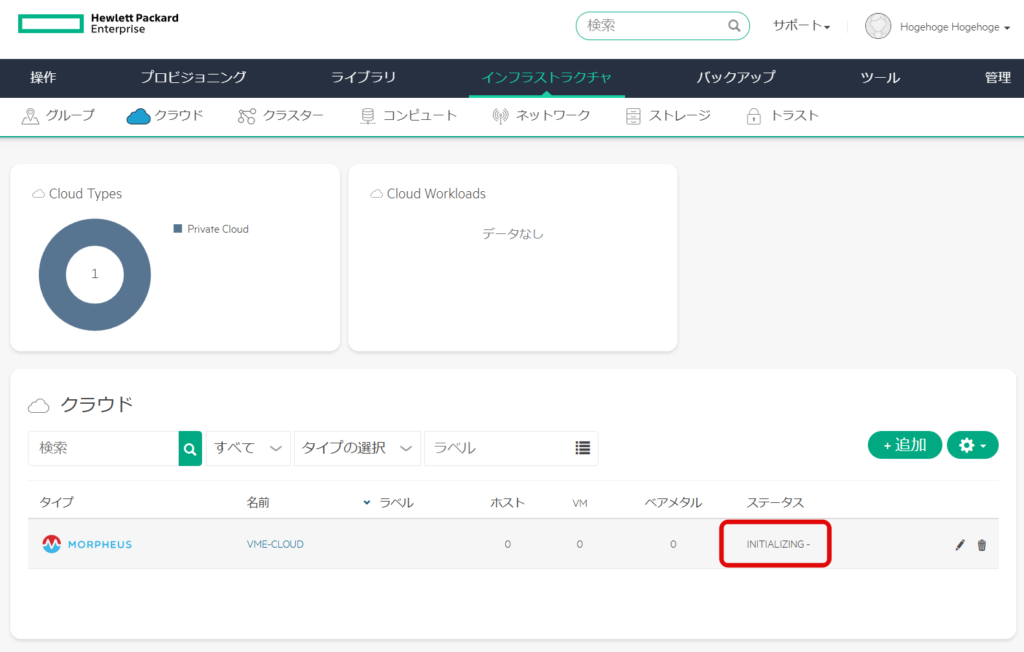
しばし待つと、「OK」に表示がかわる。

クラスターを作成するため、「クラスターの追加」を選択する。
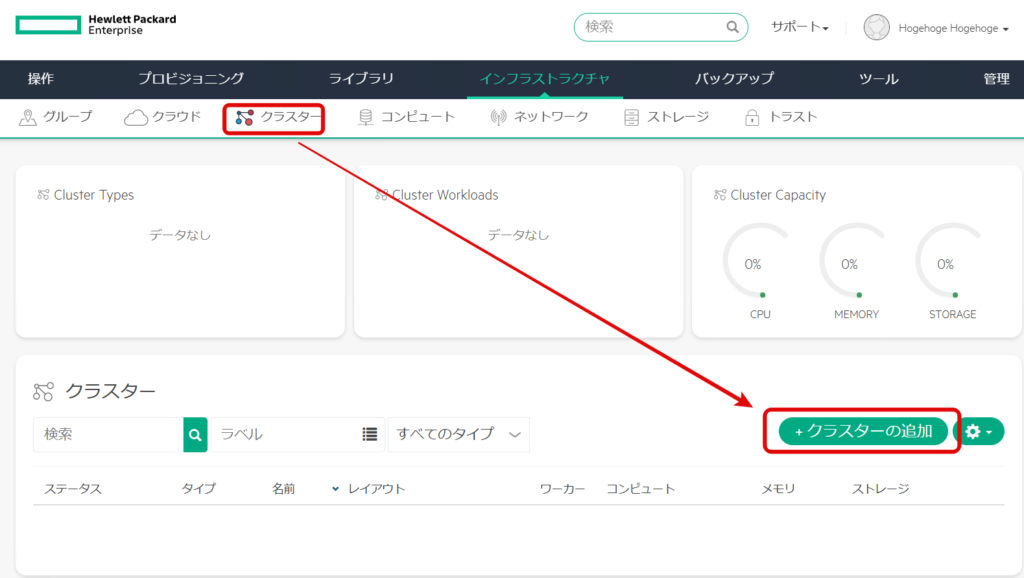
クラスタータイプで、「HPE VM」 → 「次へ」を選択する。
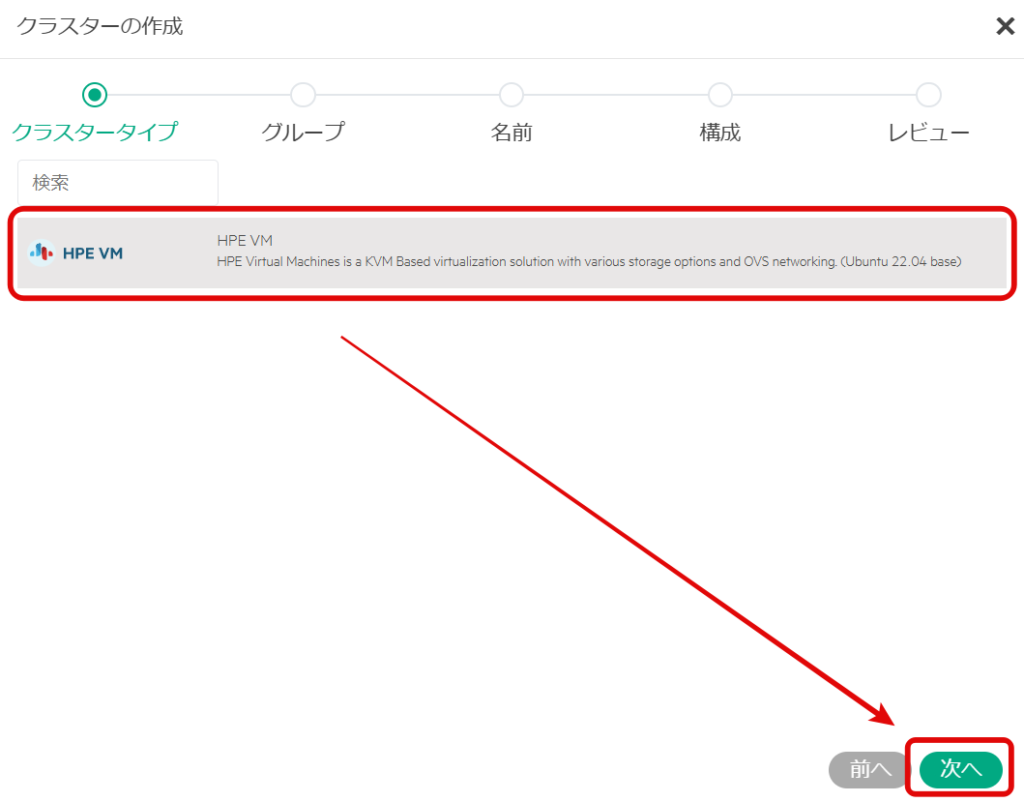
先ほど作成したグループを選択し、「次へ」を選択する。
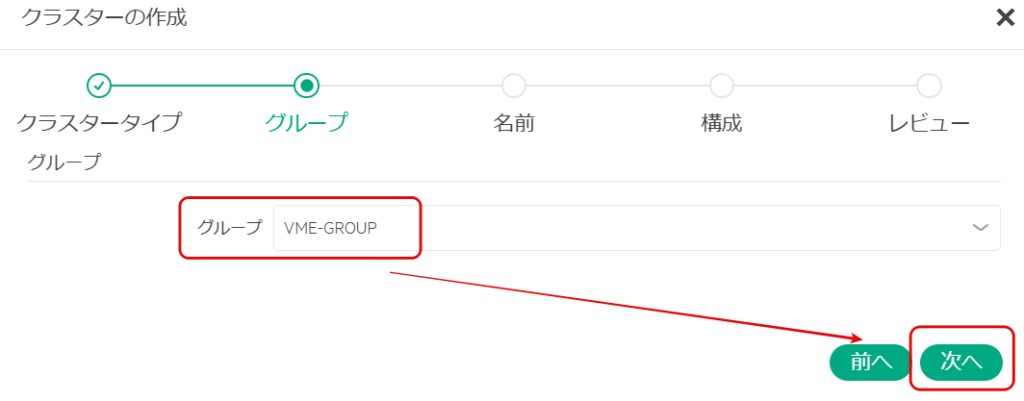
クラスター名を入力し、「次へ」を選択する。
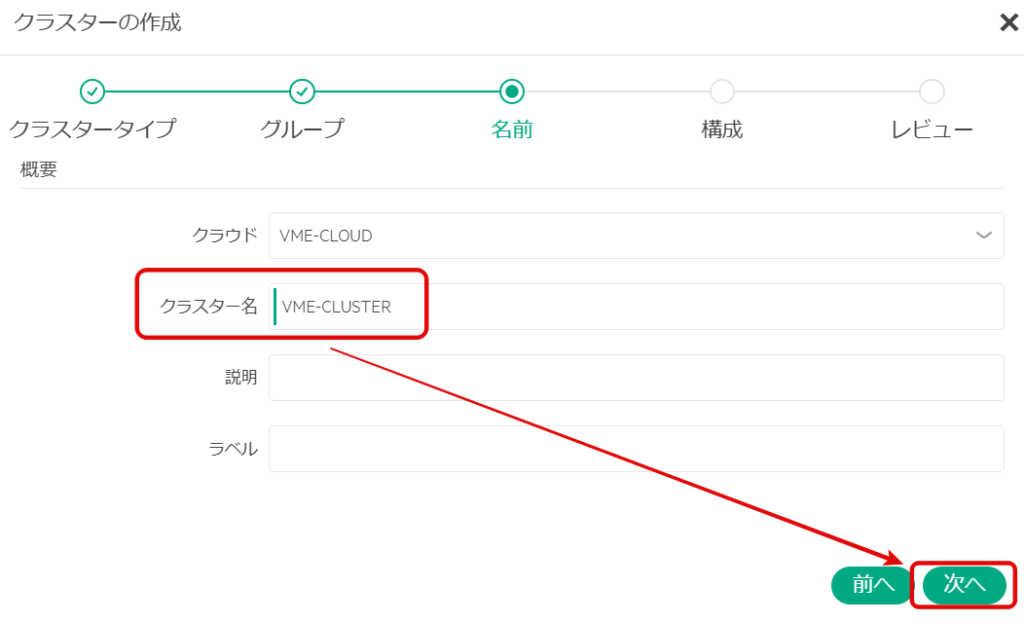
クラスターを組む、2ノード分の情報(前の記事で作成したnode01、node02の情報)を追加し、「次へ」を選択する。
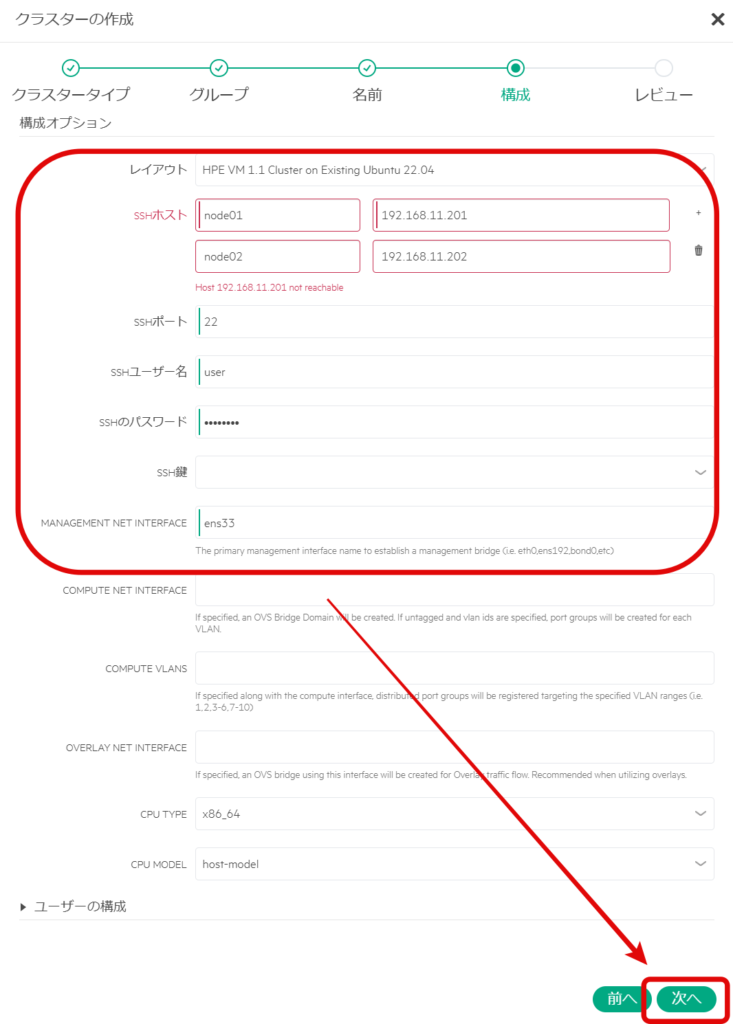
ここで、Ubuntu側のUFW(Uncomplicated Firewall:RHELでいうFirewalld、iptables的なもの)機能を無効にしていないと、エラーになるため無効、ないし設定を変更しておく必要がある。検証環境のため、下記手順で無効化している。
//ufwの設定無効化
root@node01:/mnt# ufw disable
//ufwの自動起動無効化
root@node01:~# systemctl disable ufw.service
Synchronizing state of ufw.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install disable ufw
Removed /etc/systemd/system/multi-user.target.wants/ufw.service.
root@node01:~#内容に問題がなければ、「完了」を選択する。
nodeの登録が完了するまで、しばし待つ。
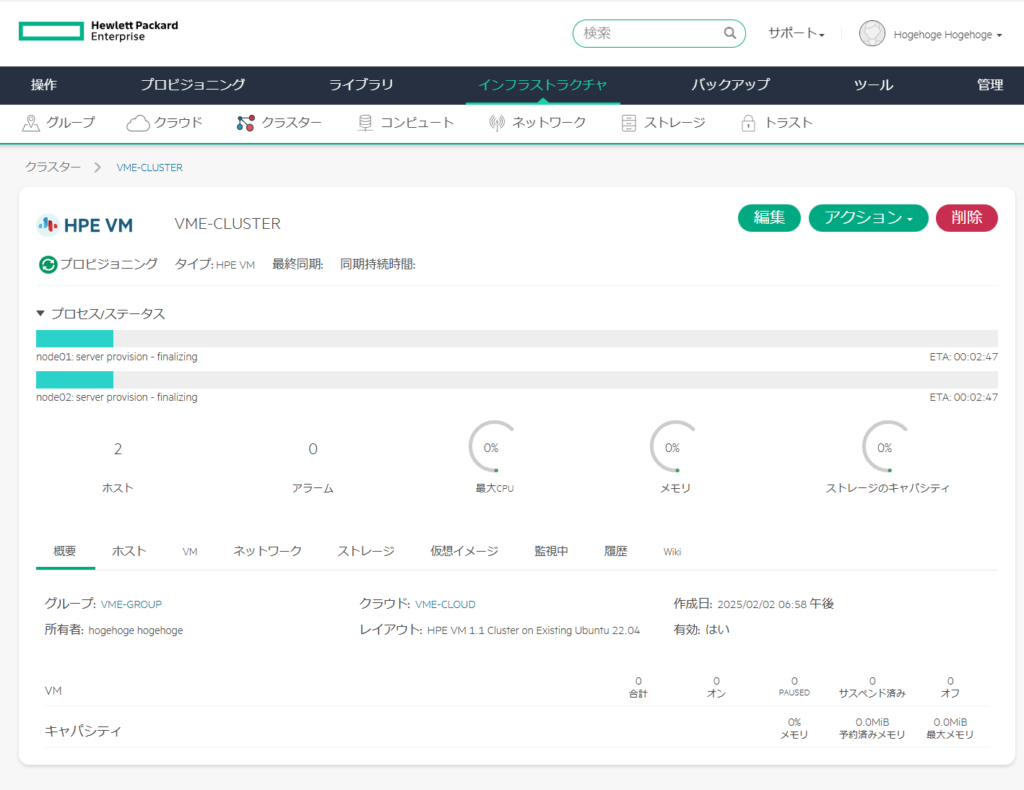
今回は2,3分くらいで登録が完了した。
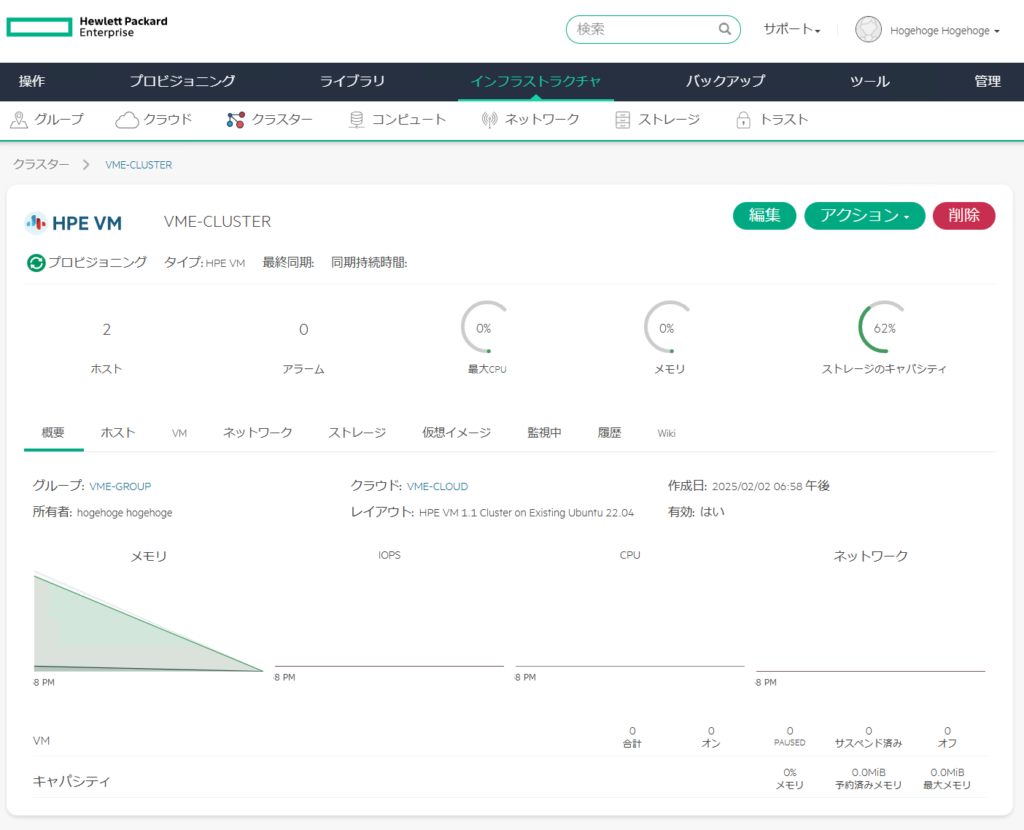
コンピュートを選択すると、登録したnode01、node02が見えている。
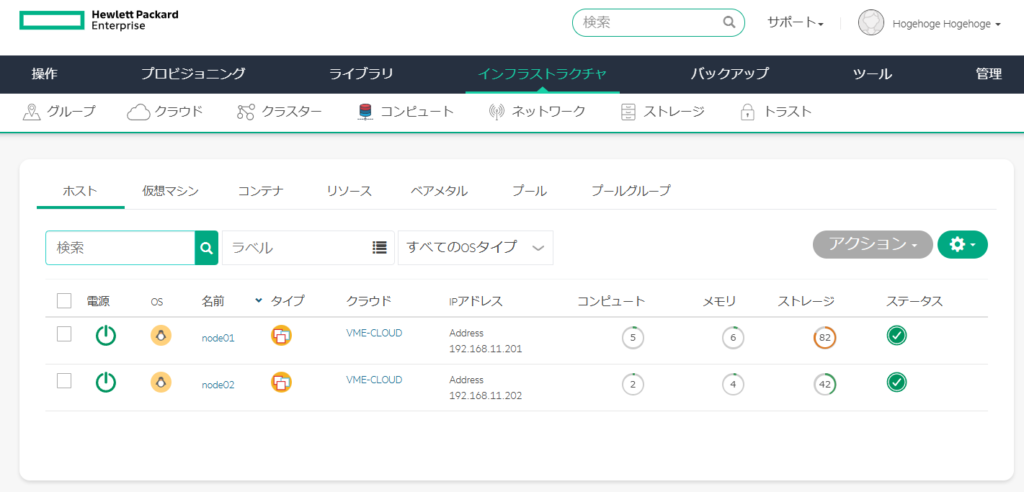
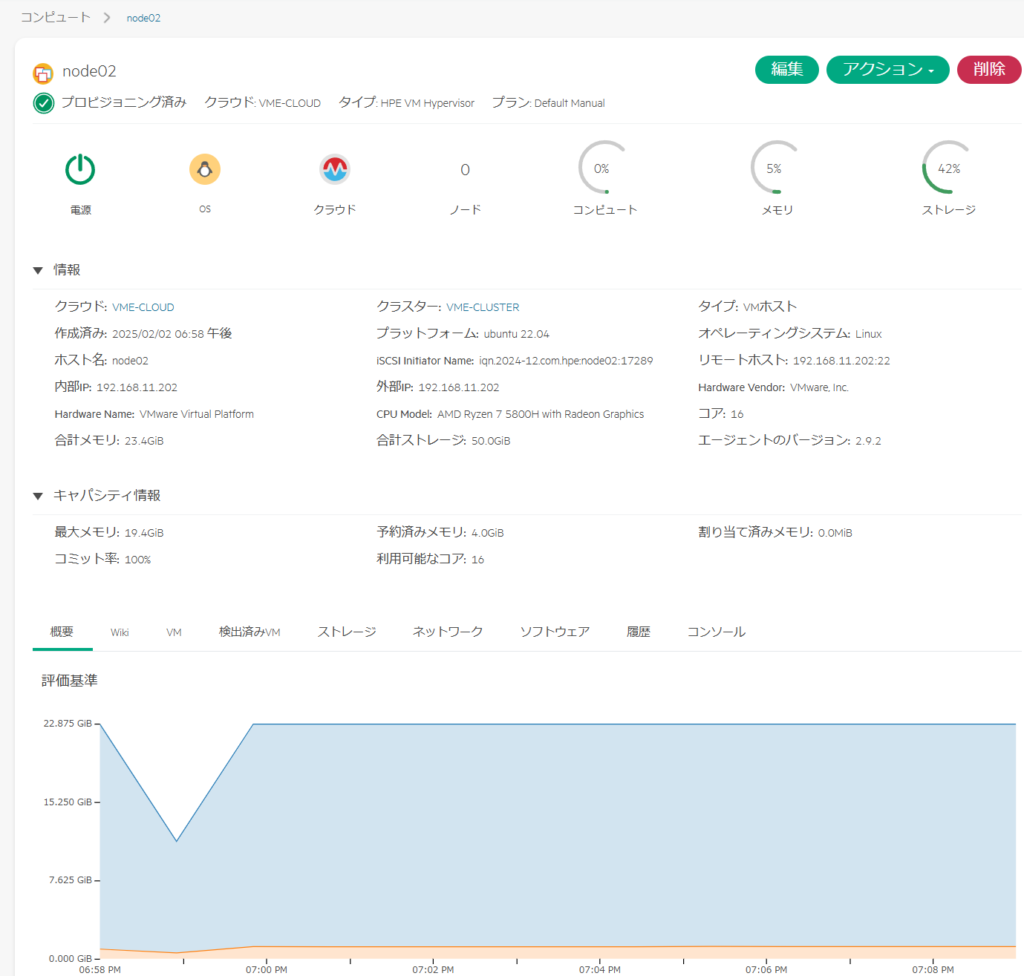
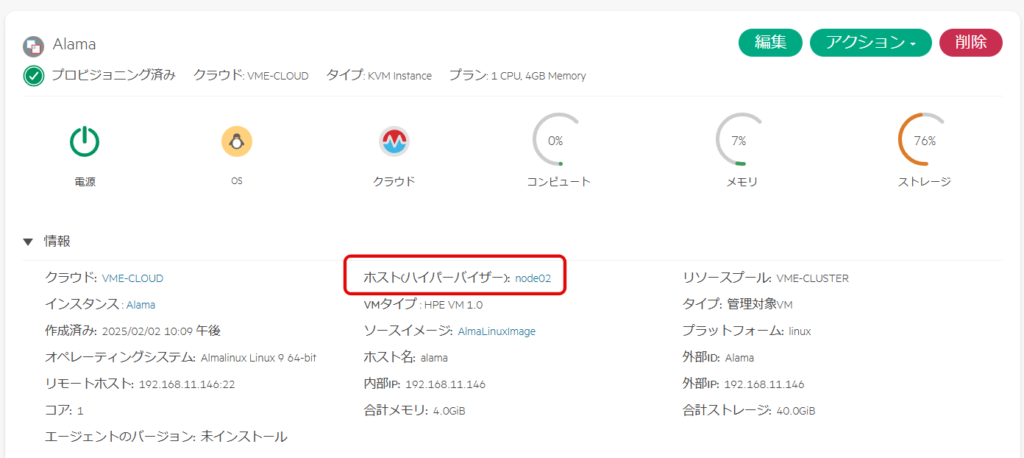
node02を選択すると、以下の内容が表示される。
共有ディスクの接続
node2台を追加したクラスターの設定が完了したため、以前の記事で作成したTureNASを登録する。
「インフラストラクチャ」 → 「クラスター」 → 「VME-CLUSTER」を選択する。
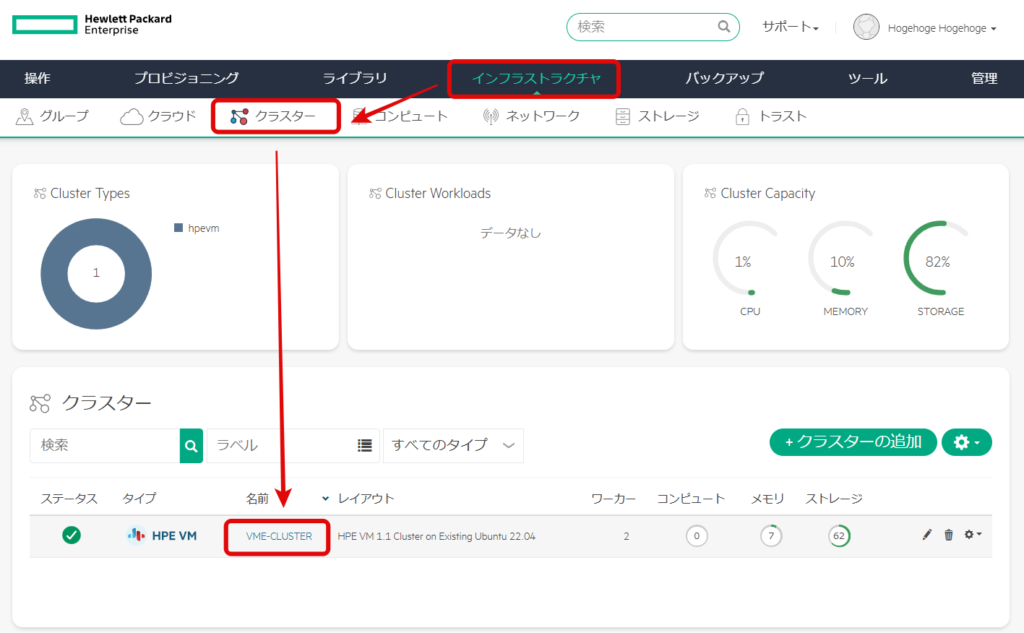
「ストレージ」を選択する。
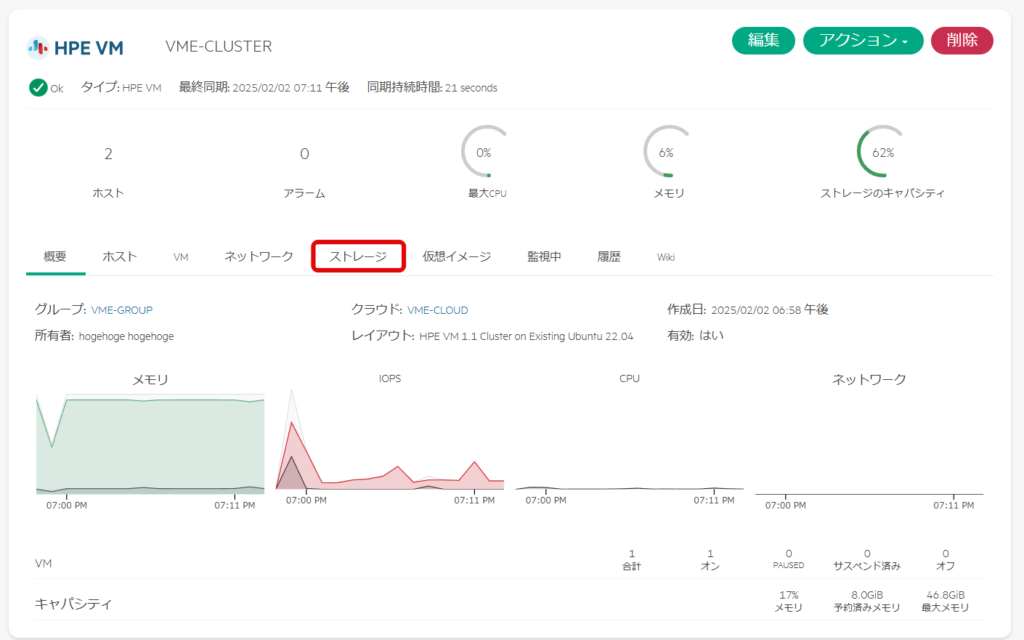
「追加」を選択する。なお、画面下部には既存のストレージ情報が見えるが、作業前のためNFSの領域は見えていない。
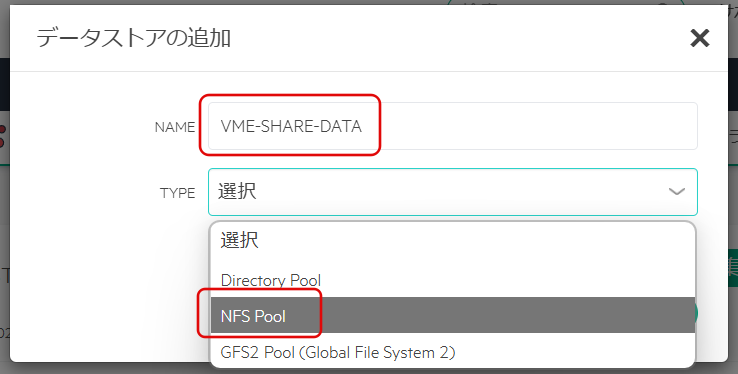
データストア名を入力し、「NFS Pool」を選択する。
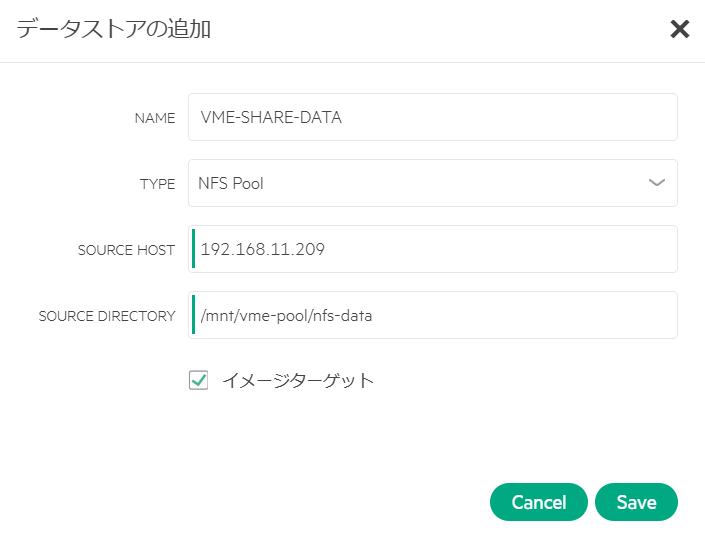
TrueNASで設定したNFSの情報を入力し、「Save」を選択する。
下図の通り、登録中の画面に遷移する。
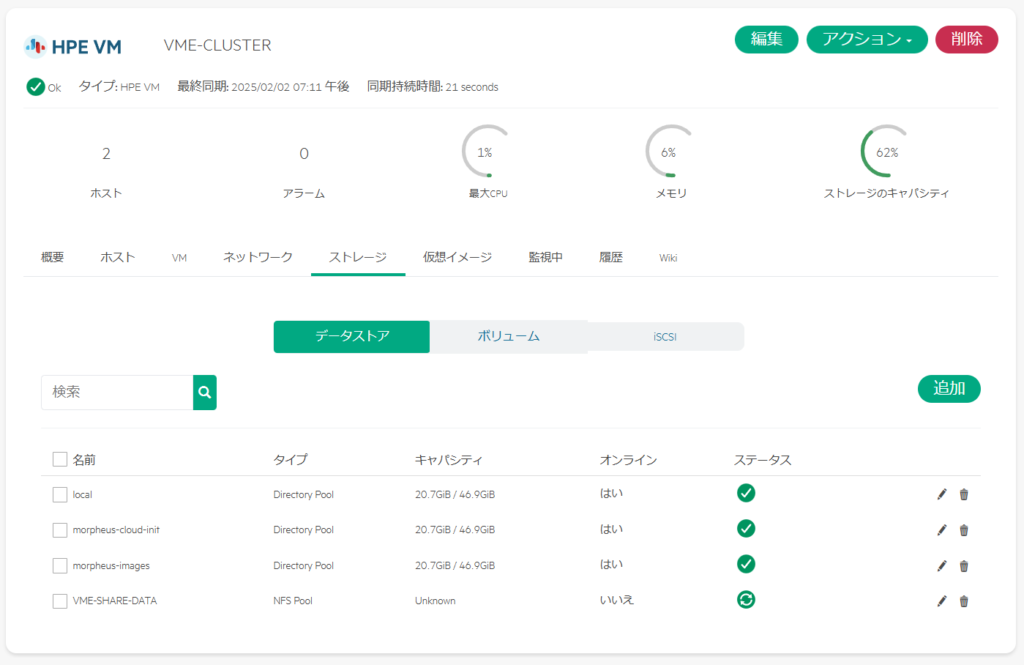
すぐに登録は完了するが、ステータスが更新されなければ、ブラウザを更新し、下図のように更新されるか確認してほしい。
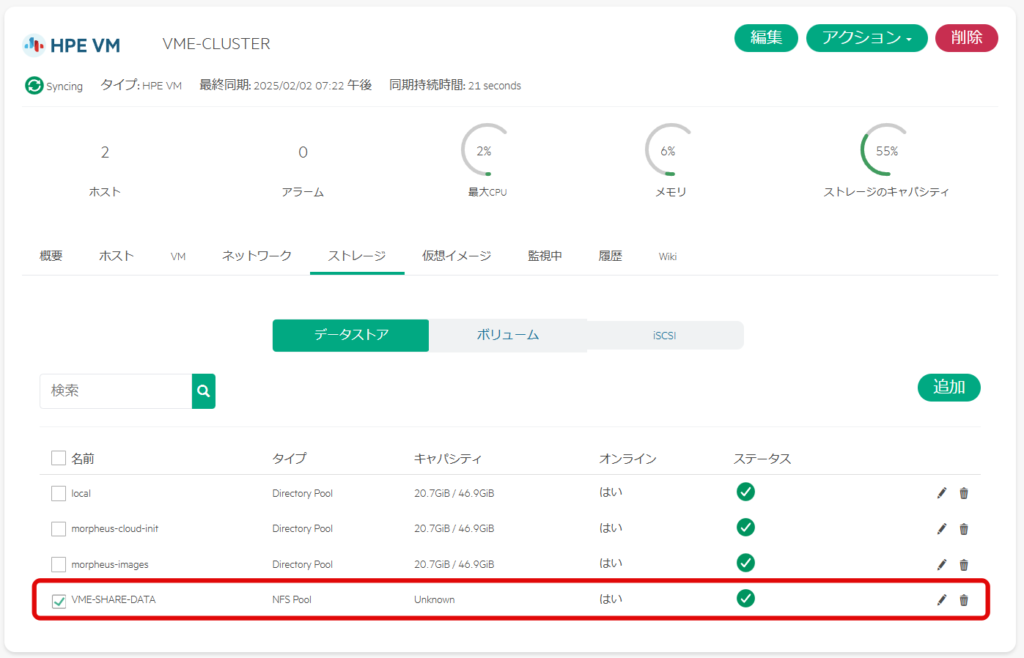
以上で、共有ディスクの接続まで完了した。
NFS登録時、以下のエラーが出力された場合、node側で何かをmountしている可能性があるため、umountで外しておくと解決するケースもある。
error: Failed to start pool def049e9-e92b-4b22-9762-f4d8cab2c05c error: internal error: Child process (/usr/bin/mount -o nodev,nosuid,noexec -t nfs 192.168.11.209:/mnt/vme-pool/nfs-data /mnt/def049e9-e92b-4b22-9762-f4d8cab2c05c) unexpected exit status 32: mount.nfs: mount point /mnt/def049e9-e92b-4b22-9762-f4d8cab2c05c does not exist
仮想マシンのプロビジョニング
3回に分けて書いてきたメモだが、これで最後となる。仮想マシンでAlmaLinuxを導入し、フェイルオーバーまで実施してみる。
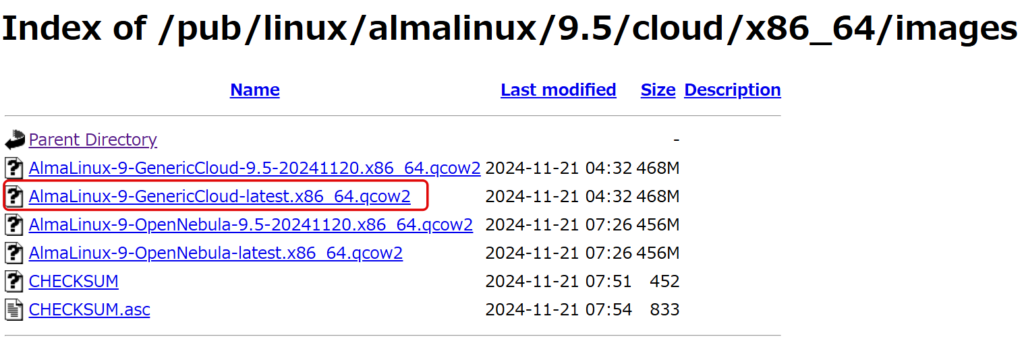
こちらのサイトから、QCOW2のイメージをダウンロードする。
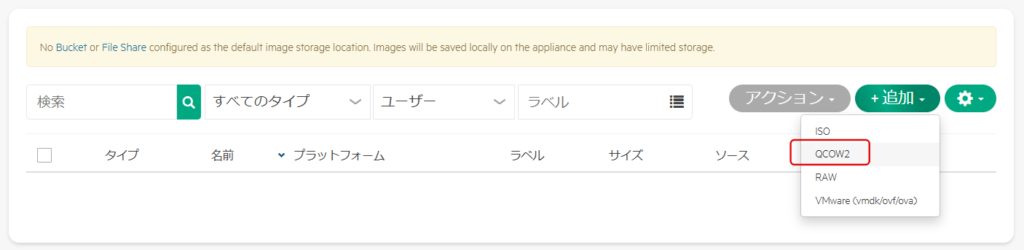
ライブラリ → 仮想イメージ → 追加 → QCOW2を選択する。
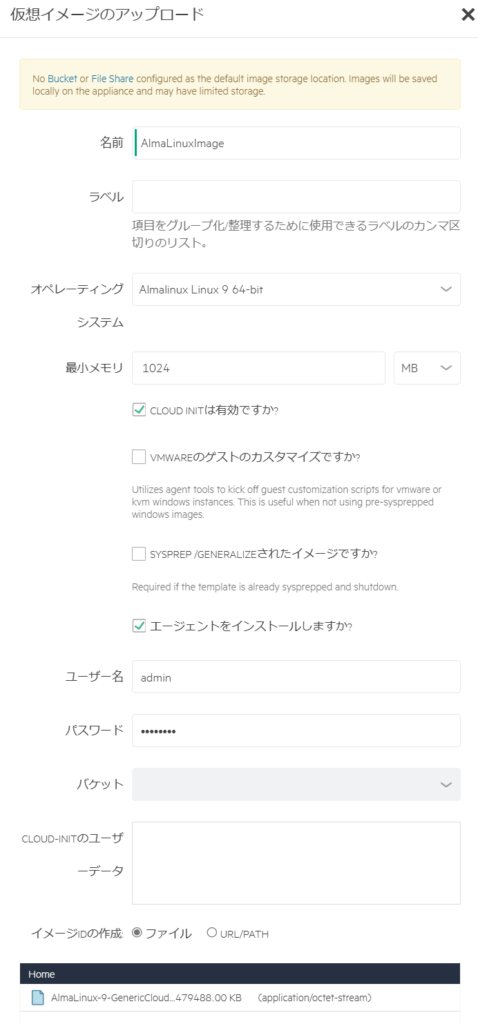
ダウンロードした仮想イメージをアップロードして、保存する。
登録された内容を確認。AlamLinuxのイメージが登録された。

ここからAlmaLinuxインスタンスの作成だ。
プロビジョニングのインスタンスから、追加を選択する。
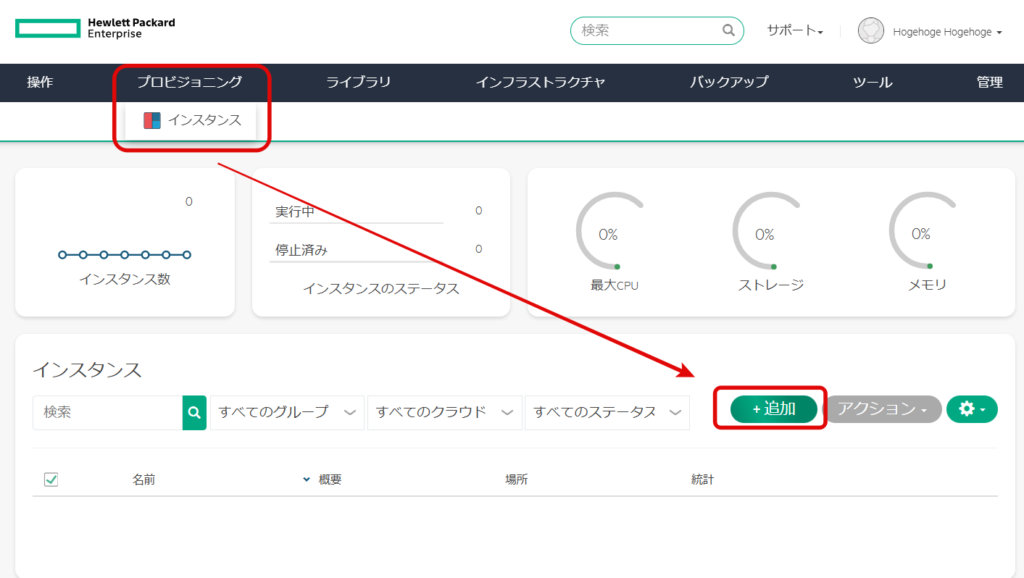
ボリュームの登録先を、接続した共有ディスクにする。イメージを先ほど登録したAlmaLinuxを選択し、他は適宜設定し、インスタンスを作成する。
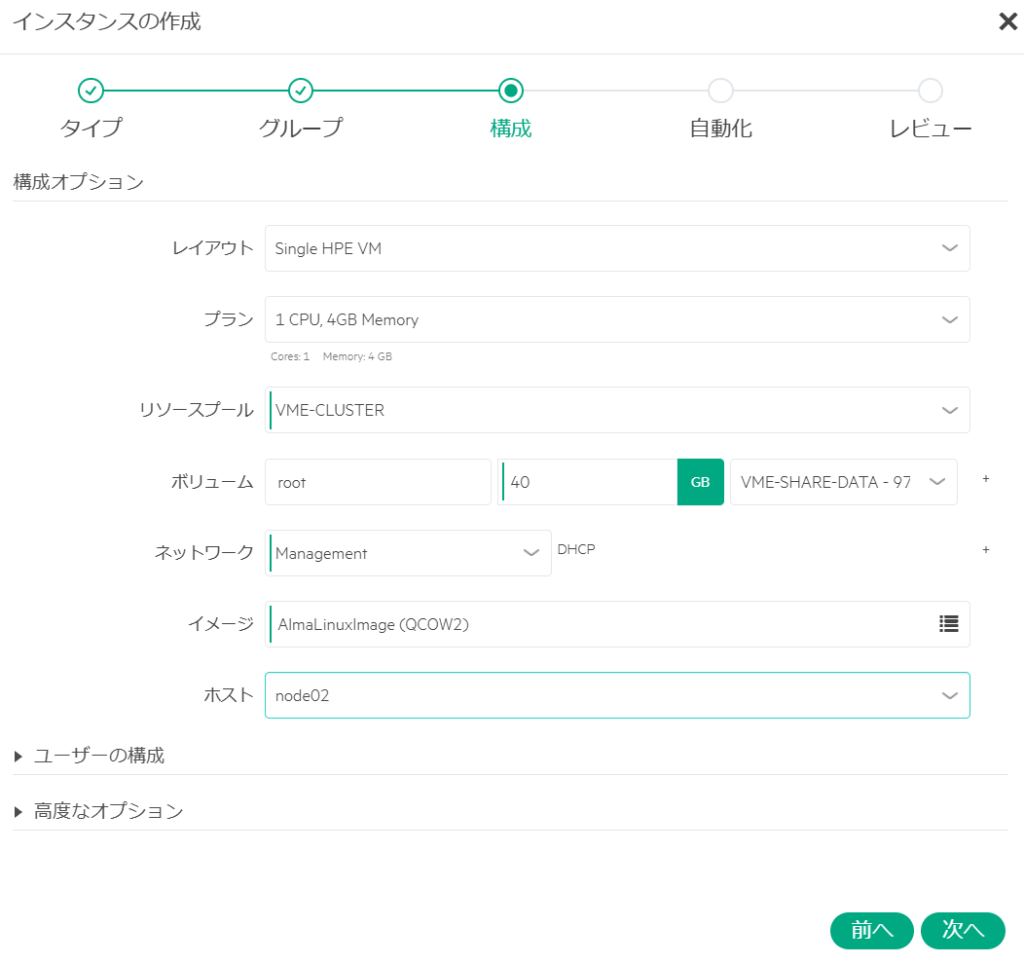
プロビジョニング中となり、数分まつ。
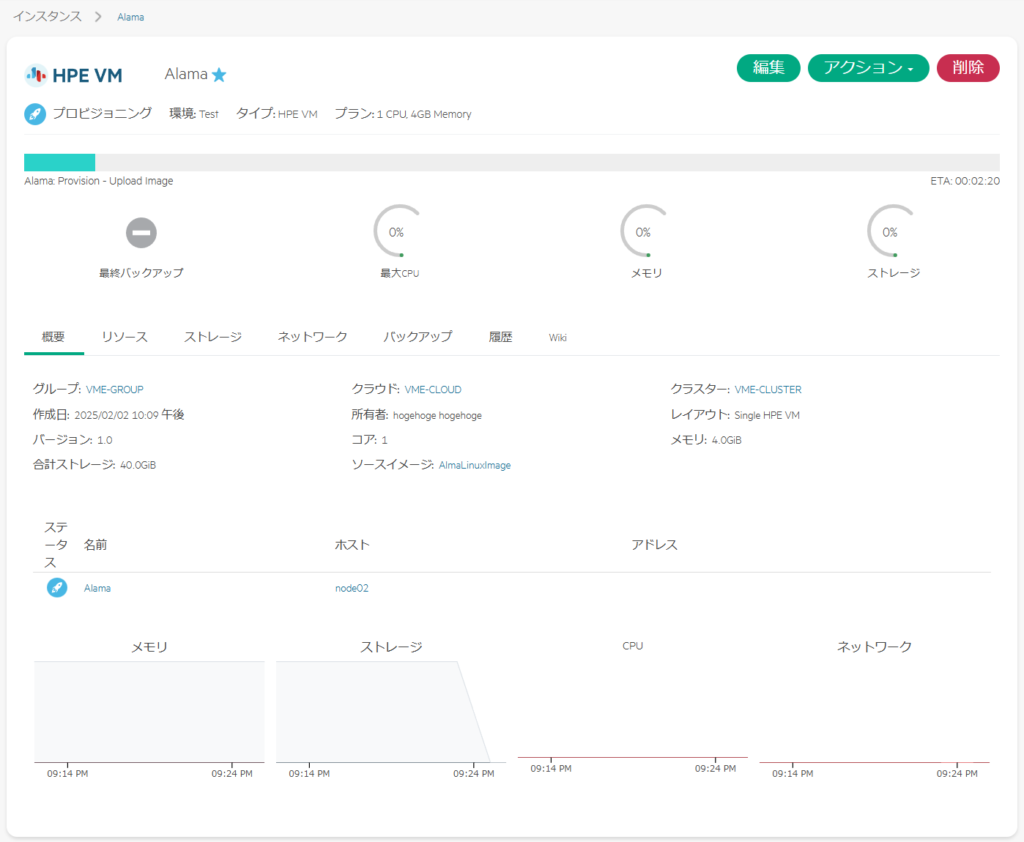
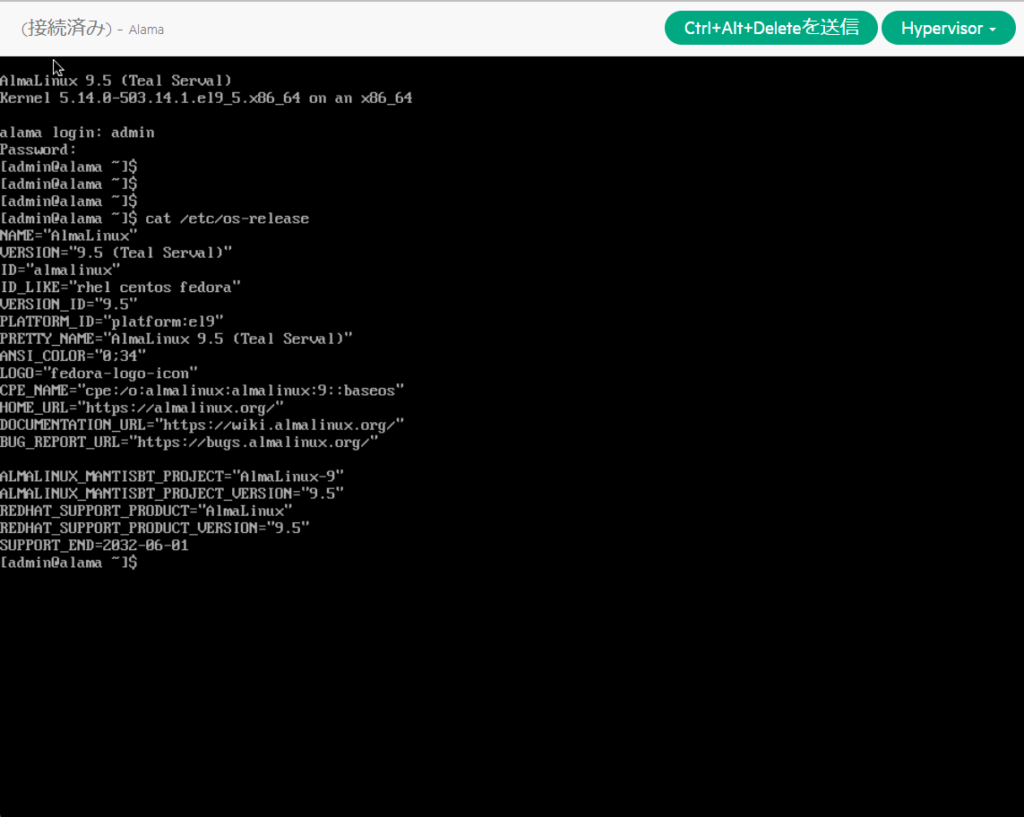
プロビジョニング後、AlmaLinuxの起動を確認するため、コンソールから接続。その後、初期設定時のユーザ名、パスワードを入力しログインできることを確認。
仮想マシンを他のノードへ移動してみる
vSphereの機能で、vMotionにあたる機能を実施してみた。
node02で稼働していることを確認。
インフラストラクチャ → コンピュート → アクション → ManagePlacementを選択する。
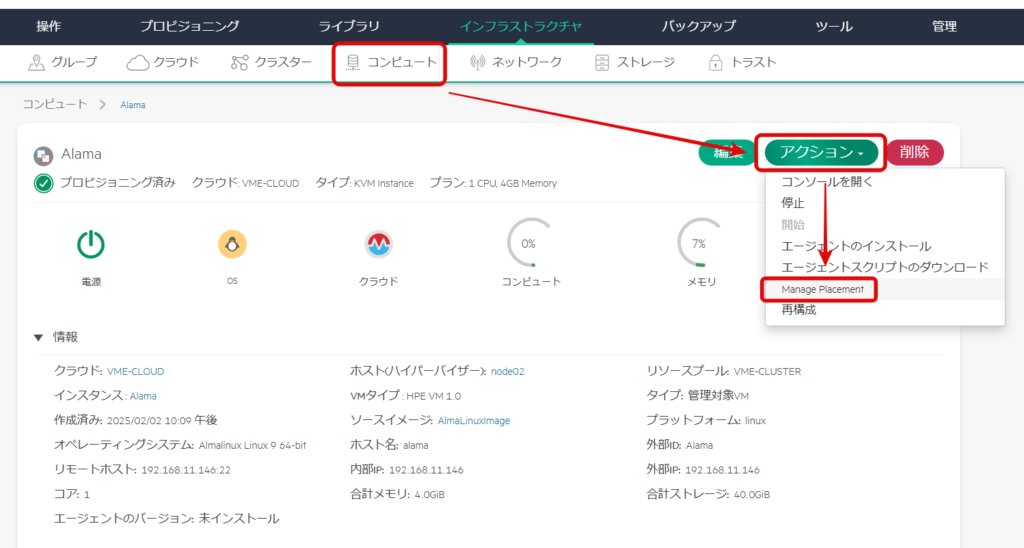
現在node02で稼働しているため、node01へ移動してみる。
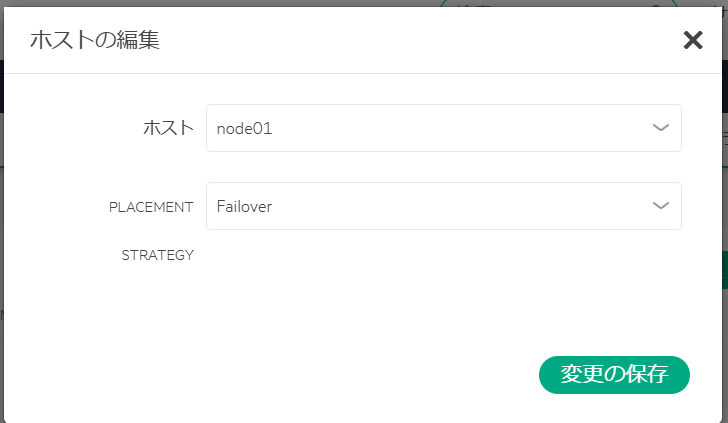
「noe01」 → 「Failover」 → 「変更の保存」を選択。
下図の通り、ホスト(ハイパーバイザー):node01となり、数秒で他のノードへ移動した。
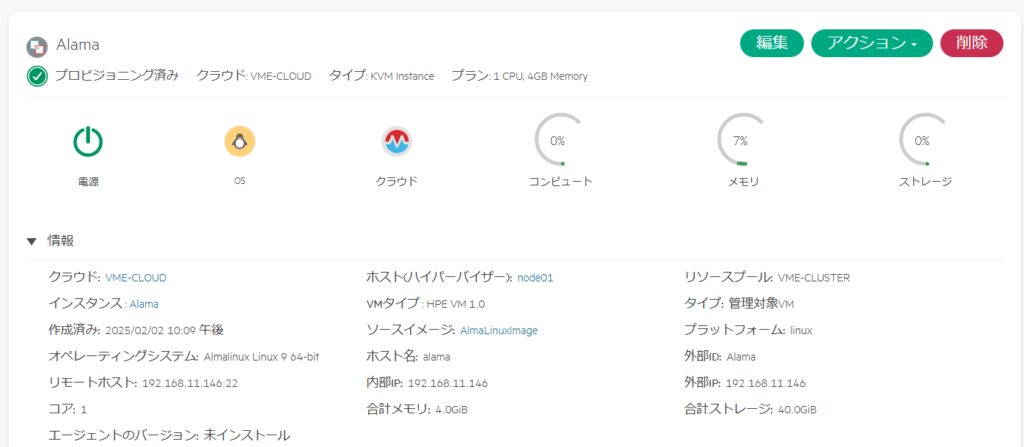
再度コンソールから確認してみるが、特に問題はなさそうだ。
これで、VME関連のメモ書きを終了とする。
※以下がVME関連の記事となる。